Emacs字节码内部说明
目录
并没有文档说明Emacs是如何将源代码编译成字节码的 — 特别是是Emacs最近进行了一次升级,开始支持静态作用域了- 这部分资料尤其少.
大多数用户对于Elisp编译的理解仅限于编译的结果是保存在 .elc 文件中,以及字节码加载起来要比未编译的Elisp要快.
对于用户来说,知道这两点基本上也足够了, GNU Emacs Lisp Reference Manual 也明确不鼓励深入了解该编译过程.
人不会去手写字节码; 字节码由编译器产出就行了. 不过为了满足你的好奇心,我们还是提供一个反汇编工具给你用吧.
什么鬼! 你怎么知道我不想手写字节码? :-) 本文就将带领你了解一下Elisp编译器的内部. 我会解释一下它的工作原理,静态作用域速度更快的秘密并展示一下如何手写字节码.
The Humble Stack Machine
Emacs的字节码解释器就是一个简单的堆栈机. 它用栈来存放lisp对象. 解释器是向后兼容的,但是无法向前兼容(即旧版本的解释器无法运行新版本的字节码). 每条指令占用1到3个字节大小. 第一个字节存放的是操作码,而第二,第三个字节存放的是操作数或者间接值. 不过有些操作数也会被压缩进操作码字节中.
写作该文时 (Emacs 24.3) Emacs共有142个操作码, 其中6已经被废弃了. 大多数的操作码都与那些常用的内置函数相关(看看那些内置函数,你会发现Elisp真的在优化文本处理上费了大劲了!). 考虑到有些操作码只是将其他操作码与操作数整合在一起,有多达27个操作码是预备给以后用的.
- opcodes 48 - 55
- opcode 97
- opcode 128
- opcodes 169 - 174
- opcodes 180 - 181
- opcodes 183 - 191
查询操作码列表的最方便途径是查询 bytecomp.el 中的内容. 不过要小心,其中有些操作码的注释已经过时了.
Segmentation Fault Warning
字节码可比普通Elisp代码要危险得多. 它甚至可能导致Emacs崩溃. 你可以试试运行一下(译者注:我在Emacs25.1下实验,并没有崩溃),
emacs -batch -Q --eval '(print (#[0 "\300\207" [] 0]))'
或者手工执行下面这段代码(请先保存好其他资料!),
(#[0 "\300\207" [] 0])
之所以产生这个segfault,并不是因为Emacs有BUG,而是是因为这段代码尝试跨界引用了常量数组后面的元素(caused by referencing beyond the end of the constants vector). 因为进行边界检查会拖慢解释器的速度,因此基于实用性的考虑,在运行期并不会进行边界检查. Emacs开发人员默认所执行的字节码肯定是由编译器产生的有效代码, 对于手写代码不保证没有问题.
永远不要尝试自己去编写字节码函数,它可能会与你的Emacs不相容从而在调用该函数时引起Emacs崩溃. 让编译器帮你做做这件事情;它产出的字节码肯定是相容的(希望是吧).
我已经提前给你打好预防针了. 现在开始玩火吧.
The Byte-code Object
字节码对象,在功能上等价于普通的Elisp数组,只不过它同时还可以作为函数来执行.
两者的元素访问时间都是常量,语法也很接近([...] vs. #[...]),对其中元素的数量理论上也是没有限制的(不过一个合法的函数至少都会有4个元素).
有两种方法可以用来创建字节码对象: 使用字面量表示法或调用 make-byte-code 函数. 跟数组的字面量一样, 字节码的字面量也不需要被引用起来.
(make-byte-code 0 "" [] 0) ;; => #[0 "" [] 0] #[1 2 3 4] ;; => #[1 2 3 4] (#[0 "" [] 0]) ;; error: Invalid byte opcode
一个字节码对象的字面量可以包括以下这些元素:
- 函数参数列表
- 表示字节码的单字节字符串
- 常量数组
- 最大栈使用量(Maximum stack usage)
- Docstring (可选,没有的话为nil)
- Interactive声明(可选)
Parameter List
参数列表依据该函数是在动态作用域下还是静态作用域下而有两种形式. 如何是在动态作用域下,那么它跟lisp代码中的参数列表一模一样.
(byte-compile (lambda (a b &optional c))) ;; => #[(a b &optional c) "\300\207" [nil] 1]
我们不能修改参数名称,因此确实也没有更简短的表示参数列表的方法了. 请记住,因为在动态作用域下,函数体执行时,这些参数是要与外部变量绑定在一起的.
当函数是在静态作用域中时,则参数列表会被打包成一个Elisp整数,用于指明有多少参数是必须的,有多少参数是 &optional 的,以及是否有 &rest 参数.
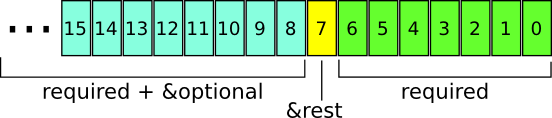
最后7位表示的是必填参数个数. 请注意,这使得静态作用域下编译后的函数最多只能有127个必填参数.
第8为指明是否有 &rest 参数(1表示有). 剩下的字节表示的是必填参数与 &optional 参数的数量和(不包括 &rest 参数).
你把整数的16进制画出来后就很清晰了,每一部分的意义都是非常明确的.
(byte-compile-make-args-desc '()) ;; => #x000 (0 args, 0 rest, 0 required) (byte-compile-make-args-desc '(a b)) ;; => #x202 (2 args, 0 rest, 2 required) (byte-compile-make-args-desc '(a b &optional c)) ;; => #x302 (3 args, 0 rest, 2 required) (byte-compile-make-args-desc '(a b &optional c &rest d)) ;; => #x382 (3 args, 1 rest, 2 required)
在静态作用域下,这些参数的名称变得无关紧要了: 它们只是单纯地与出现的位置相关. 这种紧凑的参数声明式也是静态作用域能更快的原因之一: 解释器无需在每次函数调用时都解析整个lambda表达式然后为各参数分配绑定的变量.
Unibyte String Byte-code
第二个元素是一个单字节字符串 — 它严格地以8个比特为一组,而且并不会被挡任何一种Unicode的编码形式来看待. 这种字符串必须用函数 unibyte-string 来产生,因为 string 有可能会返回多字节字符串.
为了防止lisp reader误判字符串类型,大于127的字符会以转义的8进制表示法来表示,这样就保证了字符串的字面量能够用ASCII码来表示.
(unibyte-string 100 200 250) ;; => "d\310\372"
一般来说,字节码字符串都是以135结尾的(即八进制的207). Perhaps this should have been implicit? 后面还会再讲到字节码.
Constants Vector
字节码部分只能携带有限的操作数. 大多数操作数只有几个比特大小,少数能有1个字节大小,极少的有两个个字节大小的情况.
函数是使用常量数组来存放所有的常量,函数符号以及变量符号的.
常量数组其实即iu是一个普通的Elisp数组,可以用 vector 函数或数组字面量的形式生成.
操作数则可能是指向常量数组中元素的应用或者是栈本身的索引(Operands reference either this vector or they index into the stack itself).
(byte-compile (lambda (a b) (my-func b a))) ;; => #[(a b) "\302\134\011\042\207" [b a my-func] 3]
注意,常量数组中不仅仅有变量符号,还有外部的函数符号. 若该函数处于静态作用域下,则常量数组不会包含有变量符号,只有 [my-func] 而已.
Maximum Stack Usage
该部分为字节码占用的最大栈空间. 该值本来可以通过字节码字符串本身来计算出来, 但为了让解释器能够快速发现栈溢出的情况,该值被预先计算好了放在这里. 若该值算少了,可能也会让Emacs崩溃.
Docstring
这是最简单的部分了,而且完全可以省略. 它一般就是 docstring 本身, 不过如果docstring特别大的话,也可能是一个 cons cell 指明了docstring可以从哪个elc文件的哪个位置开始读到. 之所以只需要记录docstring的开始位置是因为解释器使用lisp reader来读取该字符串,因此能够正确地识别出结束的位置.
Interactive Specification
若该部分存在且为非nil,则表示该函数是可交互的函数. 它的值就是函数定义源代码中 interactive 语句中的内容.
(byte-compile (lambda (n) (interactive "nNumber: ") n)) ;; => #[(n) "\010\207" [n] 1 nil "nNumber: "] (byte-compile (lambda (n) (interactive (list (read))) n)) ;; => #[(n) "\010\207" [n] 1 nil (list (read))]
interactive语句并不会被编译成字节码. 这通常没什么影响,因为根据定义,这部分代码一般需要等待用户输入. 不过它确实会拖慢键盘宏的回放速度.
Opcodes
下面这些操作码都是与变量,栈和常量存取相关的, 其中大部分都自带操作数.
- 0 - 7 : (stack-ref) 栈引用
- 8 - 15 : (varref) 变量引用(from constants vector)
- 16 - 23 : (varset) 变量设置(from constants vector)
- 24 - 31 : (varbind) 变量绑定(from constants vector)
- 32 - 39 : (call) 函数调用(immediate = number of arguments)
- 40 - 47 : (unbind) 变量解绑(from constants vector)
- 129, 192-255 : (constant) 常量数组的直接访问
除了最后那批指令,每种指令以8个为一组. 其中排在第N位的指令表示操作的是第N个值.
比如,指令 2 拷贝栈的中第三个值到栈顶. 而指令 9 表示将常量数组中第二个元素所表示变量的变量值压入栈中.
不过这写指令组中的第7,第8条指令很特殊,它们额外接受一个/两个字节的操作数字节. 第7条指令接受一个字节的操作数而第8条指令接受两个字节的操作数. 不管处于哪个平台,这两个字节的操作数都遵循 little-endian 的字节序.
下面,我们来人工创建一个字节码函数,该函数会返回全局变量 foo 的值. 每个操作码都有一个 byte-X 的常量与之相对应,所以我们无需记忆这些操作码的具体值.
(require 'bytecomp) ; named opcodes (defvar foo "hello") (defalias 'get-foo (make-byte-code #x000 ; no arguments (unibyte-string (+ 0 byte-varref) ; ref variable under first constant byte-return) ; pop and return [foo] ; constants 1)) ; only using 1 stack space (get-foo) ;; => "hello"
Ta-da! 我们成功地手写了一个字节码函数. 我这里保留了 + 0 是为了方便我以后修改偏移量.
下面这个函数的功能也是一样,只是没那么高效而已.
(defalias 'get-foo (make-byte-code #x000 (unibyte-string (+ 3 byte-varref) ; 4th form of varref byte-return) [nil nil nil foo] 1))
如果 foo 在常量数组中排第10位的话,我们就需要使用能接受1字节操作数的操作码了.
下面函数也是一样的功能,但是不够高效.
(defalias 'get-foo (make-byte-code #x000 (unibyte-string (+ 6 byte-varref) ; 7th form of varref 9 ; operand, (constant index 9) byte-return) [nil nil nil nil nil nil nil nil nil foo] 1))
动态作用域下的代码会大量地使用 varref 指令,而静态作用域下的代码很少使用到这个指令(只有在访问全局变量时才用), 取而代之的是 stack-ref, 而 stack-ref 的速度相对要快.
这也是两种调用约定(calling conventions)的不同之处.
Calling Convention
每种作用域都有它们自己的调用约定. 在这里你会了解到Stefan Monniner为编译器加上静态作用域是多么重要的一项升级.
Dynamic Scope Calling Convention
回头来看看字节码对象力的参数列表元素, 动态作用域函数保留完整的参数名称. 在指向函数前,解释器需要检查lambda列表并用 varbnd 指令将变量跟参数绑定起来.
如果调用者已经被编译成字节码了, 那么栈中的每个参数都需要一个一个地弹出来与变量进行绑定, 然后为了被函数能够访问,又要再压回栈中(varref). 每次函数调用时,都需要对参数进行这么一番折腾.
Lexical Scope Calling Convention
而在静态作用域下,字节码中并不包含参数名称,因为编译器已经将局部变量转换成了栈偏移量了.
当调用静态作用域函数时, 字节码解释器会对照表示参数列表的那个整数,来检查参数个数是否一致,然后对每个没有提供参数值的 &optional 参数都将nil压入栈内, 如果函数有定义 &rest 参数,那么多出来的那些参数会被组成一个list,再被压入栈中.
这样一来,函数就可以直接通过栈来访问它的参数了,而无需通过变量名来跳转. 甚至函数可以直接使用该参数而无需通过栈来访问.
;; -*- lexical-binding: t -*- (defun foo (x) x) (symbol-function #'foo) ;; => #[#x101 "\207" [] 2]
foo 的字节码只有一条指令: return. 函数的参数已经入栈所以无需而外的操作.
比较奇怪的是,这里最大栈使用量错误地标注成了2,不过这也没关系,并不会造成解释器崩溃.
;; (As of this writing `byte-compile' always uses dynamic scope.) (byte-compile 'foo) ;; => #[(x) "\010\207" [x] 1]
It takes longer to set up (x is implicitly bound), it has to make an explicit variable dereference (varref), then it has to clean up by unbinding x (implicit unbind). 毫无疑问,静态作用域要更快一些!
值得注意的是,有一个 disassemble 函数可以帮你理解字节码.
(disassemble #'foo) ;; byte code: ;; args: (x) ;; 0 varref x ;; 1 return
Compiler Intermediate “lapcode”
Elisp字节码编译器支持一种叫做 lapcode (“Lisp Assembly Program”) 的中间语言, 它要比直接使用字节码方便的多.
lapcode 基本上可以看成是基于s表达式的汇编语言. 它为每个操作码都提供了一个名称,并将操作码和操作数作为一个整体来处理.
一个lapcode程序就是一个由指令组成的list,而每条指令又是一个行为 (opcode . operand) 的cons cell.
比如,我们可以这样用lapcode来改写最后那个版本的 get-foo 函数.
(defalias 'get-foo (make-byte-code #x000 (byte-compile-lapcode '((byte-varref . 9) (byte-return))) [nil nil nil nil nil nil nil nil nil foo] 1))
我们不用关心哪个版本的 varref 的指令格式,也不用关心如何如何对2字节长的操作数进行编码. 所有的细节都由lapcode “assembler” 帮我们保定.
Project Ideas?
Emacs编译器和解释器都很好玩. 在研究过它们之后,我真的打算创建一个相关的项目来试试手. 也许是实现一门解释器支持的新语言,也许是改进编译器的优化措施,或者干脆玩一票大的,实现运行时编译Emacs字节码.
谁说不能手工编写字节码!
