eredis — An updated Emacs API – justinhj – Medium
目录
eredis --- An updated Emacs API
eredis——更新的Emacs API
属性: :CUSTOM_ID: 7a4e :CUSTOM_ID: 7 a4e :CLASS: graf graf--h3 graf--leading graf--title 级别:graf graf—h3 graf—领导graf—头衔 :name: 7a4e 名称:7 a4e
结束:
[[https://medium.com/@justinhj?source=post_header_lockup][ ]]justinhj
[[https://medium.com/@justinhj ?来源= post_header_lockup] [
]]justinhj
[[https://medium.com/@justinhj ?来源= post_header_lockup] [ ]] [[https://medium.com/@justinhj ?来源= post_header_lockup] [justinhj]]
]] [[https://medium.com/@justinhj ?来源= post_header_lockup] [justinhj]]
Nov 19 11月19日
In July 2011 I released an emacs lisp client for the Redis in-memory data structure store. You can install either from the Melpa package or just clone from Github. The current version at time of writing is 0.9.6 and you will need that or later for some of the examples below to work.
2011年7月,我为[[https://redis]发布了一个emacs lisp客户端。io/][Redis]]在内存中的数据结构存储。您可以从Melpa包安装,也可以从Github克隆。撰写本文时的当前版本是=0.9.6=,您将需要它或以后的版本才能使用下面的一些示例。
In my spare time over the last few weeks I have been steadily improving eredis by fixing bugs, adding support for multiple connections, modernizing the use of emacs lisp and adding some features like iterating and mapping over all the keys in the Redis DB. 在过去几周的业余时间里,我一直在通过修复bug、添加对多个连接的支持、更新emacs lisp的使用以及添加一些特性(如在Redis数据库中的所有键上进行迭代和映射)来稳步改进eredis。
In this article I will re-introduce eredis and describe some of these changes, as well as going into some details about how it works under the hood. 在本文中,我将重新介绍eredis,并描述其中的一些更改,以及详细介绍它是如何工作的。
Possible uses of eredis
eredis的可能用途
属性: :CUSTOM_ID: 0f3c :CUSTOM_ID: 0 f3c世锦赛 :CLASS: graf graf--h4 graf-after--p 类:graf graf—h4接枝后—p :name: 0f3c 名称:0 f3c世锦赛
结束:
- Debugging your applications. A convenient way to view the data in Redis that uses the full power of Emacs buffers and emacs lisp
-调试你的应用程序。在Redis中查看数据的一种方便方法是使用Emacs缓冲区和Emacs lisp的全部功能
- Monitoring. Using the hooks to org mode you can load a list of key/values into an org table. With lively.el you can update it periodically. Now emacs is a realtime monitoring tool!
-监控。使用挂钩到org模式,您可以将一组键/值加载到org表中。通过lively.el您可以定期更新它。现在emacs是一个实时监控工具!
- Data processing. Using iteration and reduction functions in eredis you can scan over all the keys in Redis and perform calculations on your data.
——数据处理。使用eredis中的迭代和约简函数,您可以扫描Redis中的所有键并对数据执行计算。
- Scripting and testing. Use the full power of emacs lisp to create test data or simulate users for test cases.
-脚本和测试。使用emacs lisp的全部功能来创建测试数据或为测试用例模拟用户。
Installation and preparation
**安装和准备
属性: :CUSTOM_ID: 2f92 f92 CUSTOM_ID: 2 :CLASS: graf graf--h4 graf-after--li 类:graf graf—h4接枝—li :name: 2f92 :名称:2 f92
结束:
Installation instructions can be found in the Github README.md file. 安装说明可以在Github README找到。md文件。
Next you will need access to a Redis database. You can run a local test Redis instance using Docker. There are two scripts in the github repo to let you run two instances; one on port 6380 and the other on the default port 6379. This is because you can connect to multiple Redis servers using eredis. Also note we're using Redis 5.0 so we can try out the newer commands. 接下来,您将需要访问一个Redis数据库。您可以使用Docker运行本地测试Redis实例。github repo中有两个脚本来让你运行两个实例;一个在端口6380上,另一个在默认端口6379上。这是因为您可以使用eredis连接到多个Redis服务器。还要注意的是,我们使用的是Redis 5.0,所以我们可以尝试更新的命令。
docker run -d -p 6379:6379 --name redis5_80 redis:5.0.0-alpine docker run -d -p 6380:6379 --name redis5_81 redis:5.0.0-alpine
Connections and basic commands
**连接和基本命令
属性: :CUSTOM_ID: 0fc3 :CUSTOM_ID: 0一个fc3。文件 :CLASS: graf graf--h4 graf-after--pre 类:graf graf- h4格拉夫-后-前 :name: 0fc3 :名字:0一个fc3。文件
结束:
Each connection to Redis creates an emacs process. To write a network client you use a network process. The following commands open network processes to your Redis instances. 每个到Redis的连接都创建一个emacs process。要编写网络客户端,需要使用网络进程。以下命令向您的Redis实例打开网络进程。
(require 'eredis) (setq rp (eredis-connect "localhost" 6379)) (setq rp2 (eredis-connect "localhost" 6380))
Note that the return value is a process. We can then pass that in as the final parameter to most eredis calls, so it knows where to route the command. If you omit the process it will use the last opened process by default. This ensures backwards compatibility with older eredis versions. 注意,返回值是一个进程。然后我们可以将其作为最后一个参数传递给大多数eredis调用,这样它就知道将命令路由到哪里。如果您省略了进程,它将默认使用最后一个打开的进程。这确保了与旧版本eredis的向后兼容性。
Let's try a couple of basic commands. Imagine our application stores users and the time they logged in as string key that looks like=user:ID= and a value which is the timestamp. We'll set two users that have logged in at the same time, one in each instance: 让我们尝试几个基本命令。想象一下,我们的应用程序将用户和他们登录的时间存储为string key,它看起来像=user:ID=,而值是时间戳。我们将设置两个用户同时登录,每个实例一个:
(eredis-set "user:61" "1542084912" rp) (eredis-set "user:62" "1542084912" rp2)
Now you can check the data is stored correctly: 现在你可以检查数据存储正确:
(eredis-get "user:61" rp) (eredis-get "user:62" rp2)
When we issue a Redis command it is sent to over the network using the function process-send-string and the response from Redis will be sent to an emacs buffer associated with the process. After the two commands above you'll see the buffers look like this:
当我们发出一个Redis命令时,它使用函数=process-send-string=通过网络发送,而来自Redis的响应将发送到与该进程关联的emacs缓冲区。在上述两个命令之后,你会看到缓冲区是这样的:
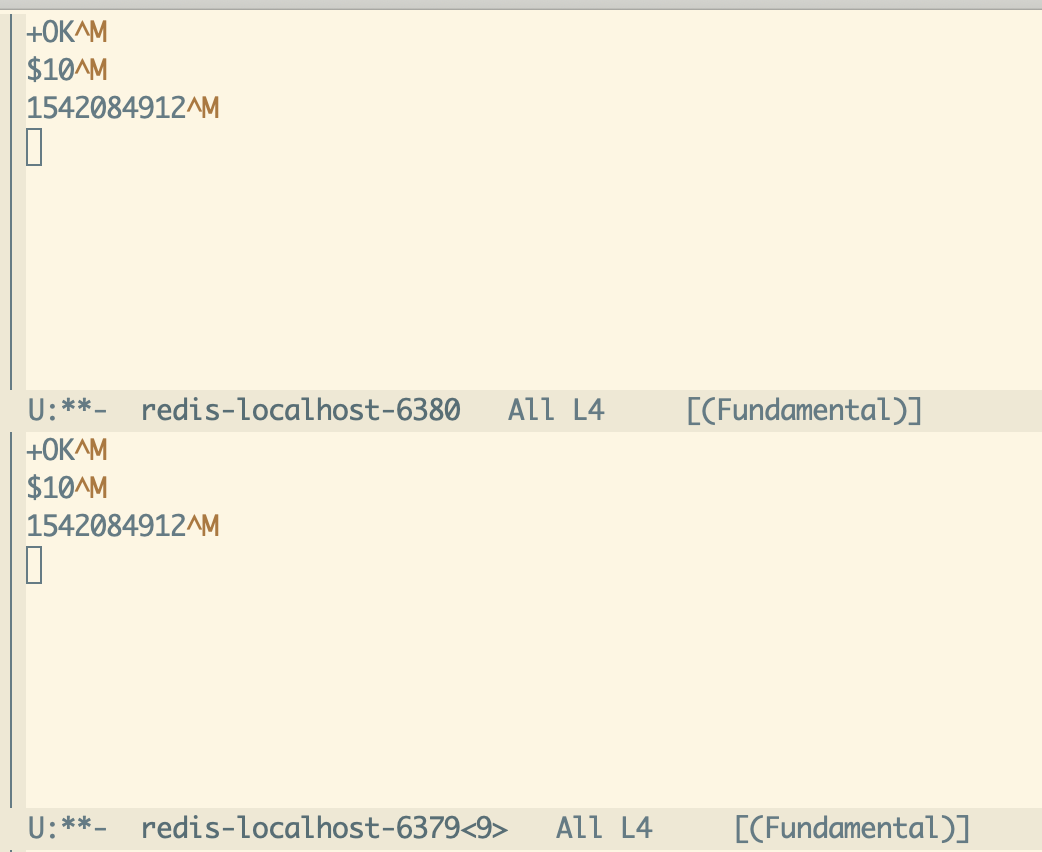 Process buffers for each Redis connection
每个Redis连接的进程缓冲区
Process buffers for each Redis connection
每个Redis连接的进程缓冲区
Notice that the buffers contain the pre-parsed RESP protocol. Using buffers in this way lets you see the history of output from Redis, which helps with debugging and also maybe useful depending on how you use eredis. 注意,缓冲区包含预解析的RESP协议。以这种方式使用缓冲区可以查看来自Redis的输出历史,这有助于调试,根据使用eredis的方式可能也很有用。
After the command is sent to Redis eredis will call accept-process-output which is a signal to Emacs to check for any data received over the network connection and put it in the buffer. This function can return immediately if there is no data, so you have to keep calling it until you've got a fully formed response.
将命令发送给Redis之后,eredis将调用=accept-process-output=,这是Emacs的一个信号,用于检查通过网络连接接收到的任何数据,并将其放入缓冲区。如果没有数据,这个函数可以立即返回,因此必须不断地调用它,直到得到一个完整的响应。
If the buffers start to get big or you want to clear them, you can do so with eredis-clear-buffer passing the process as the parameter. You can also disconnect from the process once you are done either by using the command eredis-disconnect or by killing the process in the window you get if you run the=list-processes= command.
如果缓冲区开始变大,或者需要清除它们,可以使用=eredis-clear-buffer=将进程作为参数传递。一旦完成,您还可以使用命令=eredis-disconnect=或在运行=list-processes=命令时在窗口中杀死进程,从而断开与进程的连接。
Lolwut
* Lolwut
属性: :CUSTOM_ID: 398b b: CUSTOM_ID: 398 :CLASS: graf graf--h4 graf-after--p 类:graf graf—h4接枝后—p :name: 398b :名字:398 b
结束:
Salvatore Sanfilippo recently wrote in Redis news LOLWUT: a piece of art inside a DB command about how from version 5 onwards LOLWUT will do something fun. Currently that draws a piece of randomly generated art using the braille unicode characters. eredis supports that command. Salvatore Sanfilippo最近在Redis news http://antirez.com/news/123[LOLWUT: DB命令中的一件艺术品]]中写道,从版本5开始,LOLWUT将会做一些有趣的事情。目前这幅画是用盲文unicode字符随机生成的。eredis支持该命令。
eredis-lolwut returns the lolwut art.
=eredis-lolwut=返回lolwut艺术。
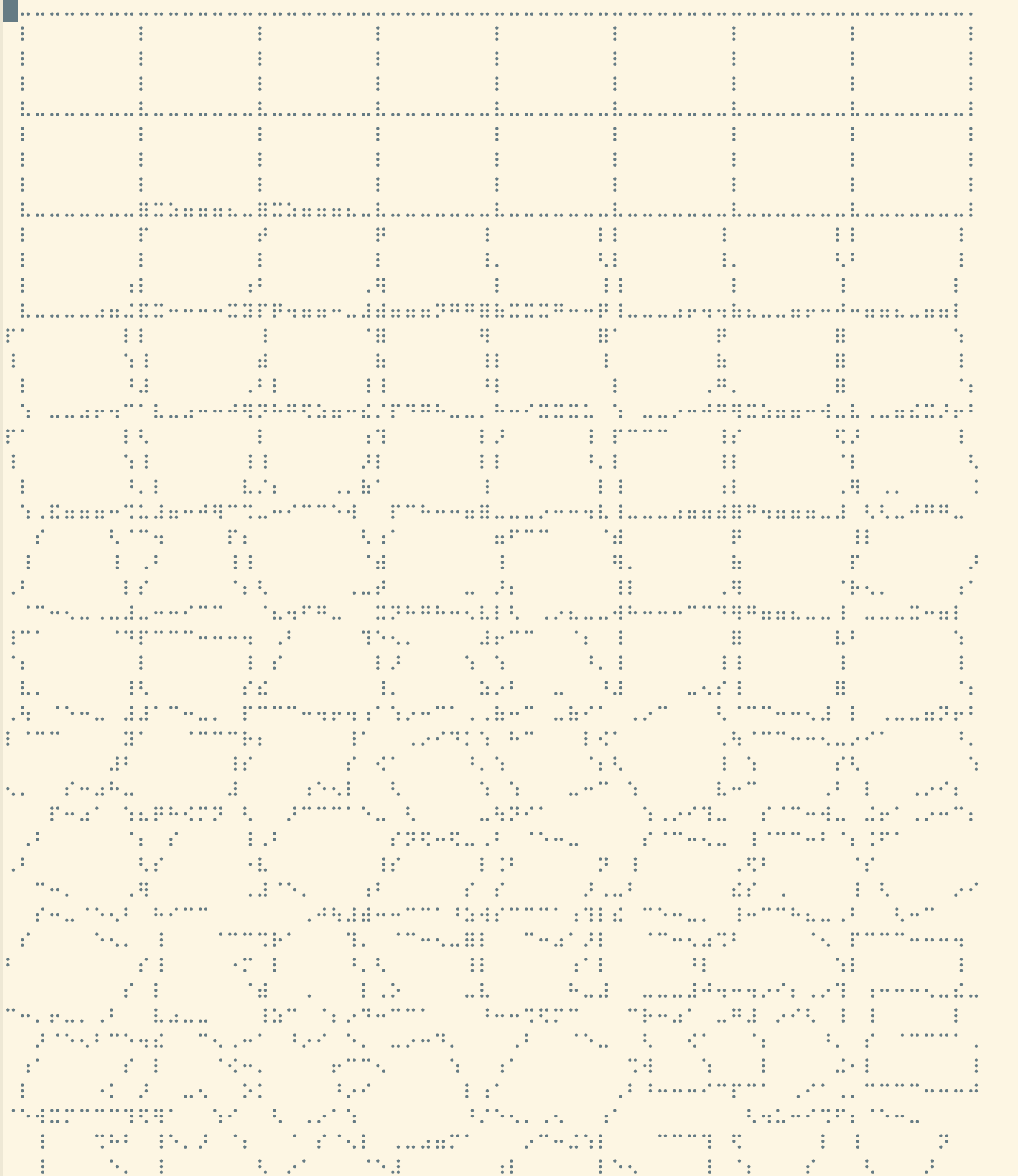 LOLWUT
LOLWUT
 LOLWUT
LOLWUT
Note that it won't look like this necessarily. In Emacs 26.1 running on macOS Mojave I had to download a few fonts before I found one that rendered correctly called Swell Braille. 注意它不一定是这样的。在macOS Mojave上运行的Emacs 26.1中,我必须下载一些字体,然后才能找到一个正确渲染的字体swbraille。
A note on multibyte string handling
关于多字节字符串处理的说明
属性: :CUSTOM_ID: 02fa :CUSTOM_ID: 02足总 :CLASS: graf graf--h4 graf-after--p 类:graf graf—h4接枝后—p :name: 02fa :名字:02足总
结束:
In early versions of eredis there was a bug reading multibyte character data. Redis, as you may know, only deals with bytes. Whatever encoding you're using for strings on the client side, you send byte strings to Redis and it sends those same strings back. In eredis the buffer is set to multibyte mode, so if you receive multibyte characters they will display correctly there: 在早期版本的eredis中,有一个读取多字节字符数据的错误。您可能知道,Redis只处理字节。无论你在客户端对字符串使用什么编码,你将字节字符串发送给Redis,它将同样的字符串发送回来。在eredis的缓冲区设置为多字节模式,所以如果你收到多字节字符,他们将正确显示在那里:
(eredis-set "hello-chinese" "你好吗") ;; "OK" (eredis-get "hello-chinese") ;; "你好吗"
So to the user of eredis everything works. But this is not automatic, take this example: 所以对eredis的用户来说一切正常。但这不是自动的,举个例子:
(length "你好吗") ;; 3 (length (string-as-unibyte "你好吗")) ;; 9
Emacs returns the length of a multibyte string as the number of characters, not the number of bytes. But Redis returns this string as follows: Emacs将多字节字符串的长度作为字符数而不是字节数返回。但Redis返回这个字符串如下:
$9 你好吗
In other words Redis sends a string of 9 bytes. You need to be careful when parsing RESP data to count actual bytes and not characters. In eredis I convert between multibyte and unibyte strings to make sure the parser works correctly, before passing the final multibyte string to the caller. 换句话说,Redis发送一个9字节的字符串。在解析RESP数据以计算实际字节数而不是字符数时,您需要小心。在eredis中,我在多字节和单字节字符串之间进行转换,以确保解析器正确工作,然后将最后的多字节字符串传递给调用者。
org mode integration
**组织模式集成
属性: :CUSTOM_ID: da6f :CUSTOM_ID da6f :CLASS: graf graf--h4 graf-after--p 类:graf graf—h4接枝后—p :name: da6f 名字:da6f
结束:
Note that you need version =0.9.6=or later for this section as I had to fix some bugs and make some improvements for this flow to work correctly. Please note that the org functions don't obey the process parameter, and they work on the last opened connection only. If you only have one connection open you should be fine. A fix for this will be in the next release. 请注意,本节需要版本=0.9.6=或更高版本,因为我必须修复一些bug并对这个流进行一些改进才能正确工作。请注意,org函数不遵守流程参数,它们只在最后一个打开的连接上工作。如果你只有一个连接打开,你应该是好的。下一个版本将对此进行修复。
Data from Redis and org-mode tables are a natural match, so I have implemented integration between the two. As an example let's create a 1000 random user login times (within the last 15 minutes) stored in the format above: 来自Redis和org-mode的数据tables是自然匹配的,因此我实现了两者之间的集成。作为一个例子,让我们创建1000个随机的用户登录时间(在过去的15分钟内)存储在上面的格式:
(let ((time-now (round (float-time)))) (dotimes (n 1000) (let ((login-time (- time-now (random (* 15 60))))) (eredis-set (format "user:%d" n) (number-to-string login-time) rp))))
Now for debugging we want to see a table with login times of some users we're interested in. That can be done like this: 现在,为了进行调试,我们希望看到一个表,其中包含我们感兴趣的一些用户的登录时间。可以这样做:
(eredis-org-table-from-keys '("user:11" "user:21" "user:31" "user:41"))
Which creates a table and inserts it in the buffer: 它创建一个表,并将其插入缓冲区:
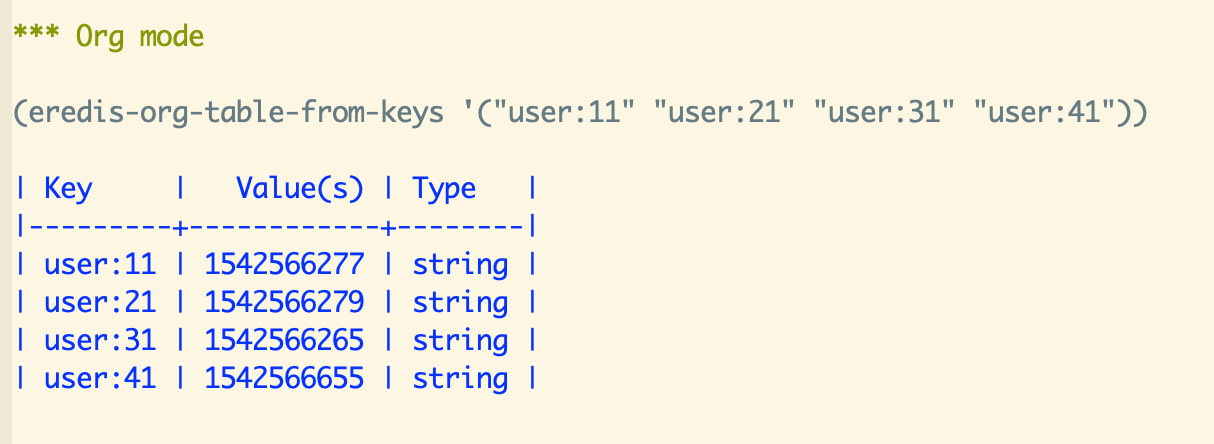 Table from keys
Table from keys
 表的键
表的键
Of course it wouldn't be any fun if the data flow was one way, so you can also edit the values (and keys) in the table and push them back up to Redis using the interactive command eredis-org-table-mset
当然,如果数据流是单向的,那就没有什么意思了,所以您还可以编辑表中的值(和键),然后使用交互式命令=eredis-org-table-mset=将它们推回到Redis
If you create the table again in another part of the buffer you'll see the values from your edit session have been stored to Redis. 如果您在缓冲区的另一部分再次创建表,您将看到来自编辑会话的值已存储到Redis。


Data processing
*数据处理
属性: :CUSTOM_ID: 18b9 :CUSTOM_ID: 18 b9 :CLASS: graf graf--h4 graf-after--figure 类:graf graf—h4接枝后—图 :name: 18b9 名称:18 b9
结束:
Another capability I recently added and that will be expanded on in future is the ability to iterate over all the keys in Redis using SCAN. Redis initially only had the KEYS * command for getting all the keys at once. Doing operations like that is a big problem when your data sets are very large. If you're working with a real time data processing system you also don't want to choke DB's of any type by pulling huge amounts of data in single queries. For that reason Redis added the SCAN command so we can iterate through pages of keys and Redis can manage making sure that particular clients don't overwhelm the system.
我最近添加的另一个功能是使用SCAN对Redis中的所有键进行迭代,这个功能在将来还会扩展。Redis最初只有=KEYS *=命令,用于一次获取所有密钥。当您的数据集非常大时,执行这样的操作是一个大问题。如果您使用的是实时数据处理系统,您也不希望在单个查询中获取大量数据而阻塞任何类型的数据库。出于这个原因,Redis添加了扫描命令,这样我们可以遍历键的页面,而Redis可以管理,以确保特定的客户端不会淹没系统。
To this end I've added (so far) two facilities for iterating and reducing the entire key set, that wrap the SCAN command and let you focus on your data processing task. In addition at each step eredis pulls the values for each key using the MGET command. Now we can safely do map and reduce type operations over the keys and values in Redis! 为此,我添加了(到目前为止)两个用于迭代和减少整个键集的工具,它们封装了SCAN命令并让您专注于数据处理任务。此外,在每个步骤中,eredis使用MGET命令获取每个键的值。现在我们可以安全地做映射和减少类型操作的键和值在Redis!
Since I'm a fan of the dash.el list library, I use Dash commands to implement these functions, and then compile each page together transparently for the caller. 由于我是dash.el列表库的粉丝,所以我使用Dash命令来实现这些函数,然后为调用者透明地编译每个页面。
Earlier we added 1000 users. Let's do a simple reduction to count them. There are two versions of this reduce function, one that also does a key name match eredis-reduce-from-matching-key-value and another that gets all of the keys eredis-reduce-from-key-value Note the function names map to the dash.el reduce-from function and conceptually does the same thing but with transparent paging across the key space.
之前我们添加了1000个用户。让我们做一个简单的简化来计算它们。这个reduce函数有两个版本,一个还执行键名匹配=eredis-reduce-from-key-value=,另一个获取所有键名=eredis-reduce-from-key-value=注意函数名映射到dash。el reduce-from function,在概念上做了相同的事情,但是在键空间中使用了透明的分页。
In this example we will simply count all of the users using the reduce. 在本例中,我们将简单地计算使用reduce的所有用户。
(eredis-reduce-from-matching-key-value (lambda (acc k v) (+ acc 1)) 0 "user:*" rp) ;; 1000
Here's a more useful example that actually uses the value (we stored a timestamp) in the reduction. We'll figure out how long each user has been logged in, total all the login times, and divide by 1000 to get the average time logged in: 下面是一个更有用的示例,它实际使用了还原中的值(我们存储了一个时间戳)。我们将计算出每个用户登录的时间,合计所有登录时间,然后除以1000得到平均登录时间:
(let ((time-now (round (float-time)))) (/ (eredis-reduce-from-matching-key-value (lambda (acc k v) (+ acc (- time-now (string-to-number v)))) 0 "user:*" rp) 1000)) ;; 2450
So the average login time is 2450 seconds, or about 40 minutes, which is because I created the test users around 40 minutes ago. 因此,平均登录时间是2450秒,即大约40分钟,这是因为我在大约40分钟前创建了测试用户。
As well as reductions you can iterate over the users using each Note that this is not mapping over the key space as that would be very unfriendly to your Emacs environment if you have a lot of data. Map creates a new list of keys and values and holds them all in memory at once. All we want to do is iterate over the pages of keys and values, execute some function for its side effect, and continue on. There's nothing stopping you materializing the entire key set in emacs should you need to, but it's not supported by the eredis default API.
此外,您可以使用=each=对用户进行迭代,请注意这不是在键空间上进行映射,因为如果您有大量数据,这对Emacs环境非常不友好。Map创建一个新的键和值列表,并将它们一次性保存在内存中。我们所要做的就是遍历键和值的页面,执行一些函数以消除其副作用,然后继续。如果需要,没有什么可以阻止您在emacs中具体化整个键集,但是eredis默认API不支持它。
(let ((most-recent-login 0)) (eredis-each-matching-key-value (lambda (k v) (let ((login-time (string-to-number v))) (if (> login-time most-recent-login) (setf most-recent-login login-time)))) "user:*" rp) most-recent-login) ;; 1542566731
Here we iterate all the keys and values and find the most recent login. Note that this could be done as a reduction too, there is some overlap between iterators and reductions. 在这里,我们迭代所有的键和值,并找到最近的登录名。注意,这也可以作为一个缩减,迭代器和缩减之间有一些重叠。
Future
*的未来
属性: :CUSTOM_ID: 16e8 :CUSTOM_ID: 16 e8 :CLASS: graf graf--h4 graf-after--p 类:graf graf—h4接枝后—p :name: 16e8 名称:16 e8
结束:
Once eredis has stabilized and supports all Redis commands without bugs it will go to version 1.0.0
一旦eredis稳定下来,并且支持所有的Redis命令,没有任何bug,那么它将进入版本=1.0.0=
Before that however, the more immediate work is going into support for stream.el which allows us to construct lazy sequences. By implementing the SCAN functionality as a lazy stream we then can better compose operations on large data sets without blowing our memory. For example you can chain a couple of maps and filters together to transform your data before a final reduce to make it a single value. 然而在此之前,更直接的工作是支持stream.el,它允许我们构造延迟序列。通过将扫描功能实现为延迟流,我们就可以更好地组合大型数据集上的操作,而不会占用内存。例如,您可以将两个映射和过滤器链接在一起,以在最终的reduce之前转换数据,使其成为单个值。
In addition the org table support will be bolstered with bug fixes and new features. 此外,org表支持还将得到bug修复和新特性的支持。
I hope you enjoyed this quick tour of eredis and find a use for it, or at the very least see that emacs lisp programming can be fun, useful and quite simple. 我希望您喜欢eredis的快速浏览并找到它的用途,或者至少看到emacs lisp编程可以是有趣的、有用的和非常简单的。
If you want to read more blog posts like this one, I also write Functional Justin over on github pages. 如果你想阅读更多类似这样的博客文章,我还写了[[http://justinhj.github]。[功能贾斯汀]]在github页面。
