搜索一百万行Lisp代码
是时候再来一次Emacs冒险了!
目前在Emacs中,没有办法找出函数或宏的所有调用者。 大多数Emacs使用者只是使用他们喜欢的文本搜索工具进行搜索。遗憾的是,纯粹的文本搜索对语法一窍不通。
我们可以做得更好。Emacs怎么能缺少疯狂的工具构建过程呢。让我们实现这一工具。
解析
大家都知道如何解析lisp吧?只需要调用 read 就行了。
事实证明,具有同像性的语言是很难解析来寻找代码出现的最初位置的。在具有单独AST的语言中,AST类型包括文件位置。而在lisp中,你只有…一个列表。没有其他任何东西。
I briefly explored writing my own parser before coming to my senses. Did you know the following is legal elisp? 在意识到这一点之前,我简单地探索了下如何编写自己的解析器。你知道以下是合法的elisp吗?
;; Variables can start with numbers: (let ((0x0 1)) ;; And a backquote does not have to immediately precede the ;; expression it's quoting: ` ;; foo (+ ,0x0))
天啊!。
不管怎样,我完全是受到了el-search中类似功能的启发. read 将光标移动到被读表达式的结尾,然后你可以使用 scan-sexps 来查找表达式的开头位置。
使用这种递归技术,您可以找到文件中每个form的位置。
分析
好的,我们已经解析了代码,保留了代码的对应位置。那么哪些form看起来像函数调用呢?
这需要一点思考。这里有一些棘手的例子:
;; Not references to `foo' as a function. (defun some-func (foo)) (lambda (foo)) (let (foo)) (let ((foo))) ;; Calls to `foo'. (foo) (lambda (x) (foo)) (let (x) (foo)) (let ((x (foo))) (foo)) (funcall 'foo) ;; Not necessarily a call, but definitely a reference to ;; the function `foo'. (a-func #'foo)
我们不能简单地遍历列表: (foo) 可能是一个函数调用,也可能不是,这取决于上下文。
为了建模上下文,我们构建一个“path”来描述当前form的上下文位置。
path就是一个列表,它显示了所有闭包form的第一个元素,以及我们在其中的位置。
例如,给定代码 (let (x) (bar) (setq x (foo))),当我们查询 (foo) 时,我们构建的path为 ((setq . 2)(let .3)).
这为我们提供了足够的上下文来识别普通代码中的函数调用。“啊哈!有经验的lisper会说。“宏怎么办呢?”
elisp-refs可以理解一些常见的宏。大多数宏只是计算它们的大部分参数而已。这意味着我们可以遍历form并找出大多数函数调用。
这并不完美,但在实际中效果很好。我们还提供了 elisp-refs-symbol 命令,该命令查找对某个符号的所有引用,而不管它在form中的位置如何。
性能
事实证明,Emacs有大量的elisp。我当前的实例已经加载了75万行代码。 Emacs实际上是惰性地加载文件,所以这仅仅只是我用到的功能的代码量!
所以,还需要一点优化。我写了一个基准脚本,并学会了如何让elisp运行得更快。
首先, 不干活. elisp-refs需要计算form的位置,以便用户可以跳转到文件的正确位置。但是,如单form不包含任何匹配项,则根本不需要进行这种昂贵的计算。
其次, 找捷径. Emacs有一个鲜为人知的变量 read-with-symbol-positions.
该变量在解析form时会报告读取到的所有符号。如果我们在寻找 some-func 的函数调用,而form中并没有对符号 some-func 的引用,我们可以完全跳过这个form。
第三, 使用C函数. CS算法告诉我们,构建散列映射可以让您快速查找。
但在elisp-refs中,我们使用 assoc 在小型alists中查找,这是因为C函数速度很快,而大多数列表都不够大,无法从O(1)查找中获益。
第四,不写 纯函数. Elisp提供了各种方法来保存当前buffer的状态,特别是 save-excursion 和 with-current-buffer. 但这种记录原数据的方法非常昂贵,因此elisp-refs只创建自己的临时buffer并修改它们。
当其他方法都失败时,我们采取 作弊 的方法让elisp-refs报告它的进展,这并没有使它更快,但它确实感觉像是变快了。
显示
我们有一些可用的东西让我们可以在不到10秒的时间内搜索当前Emacs实例中的所有代码。我们时如何显示结果的呢?
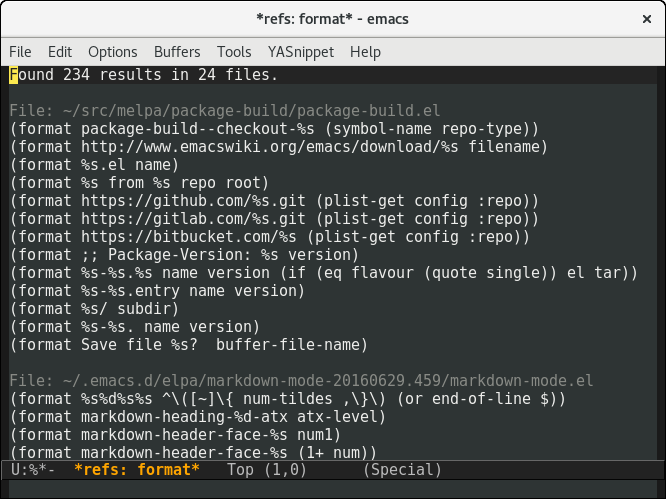 第一个原型,只显示匹配的form
第一个原型,只显示匹配的form
最初,我只是在结果buffer中显示每个匹配的form。但后来发现,原来上下文是有用的,所以又把匹配form其余的部分也加入了进来。同时为了避免混淆,我在匹配的代码部分划了下划线。
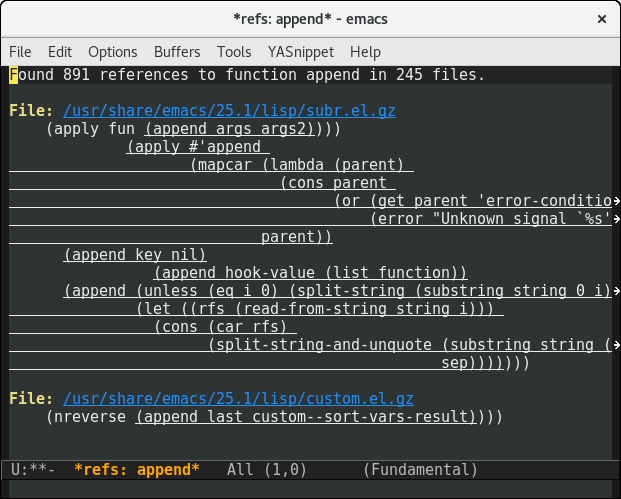 第二个原型,添加上下文和自定义样式
第二个原型,添加上下文和自定义样式
第二个原型还有一些定制的样式。这是一项改进,但它强制所有Emacs主题作者添加支持包中定义的外观。
它仍然达不到我的要求。当我遇到UI问题时,我会问“magit会做什么?”我认为magit会利用现有的Emacs样式。
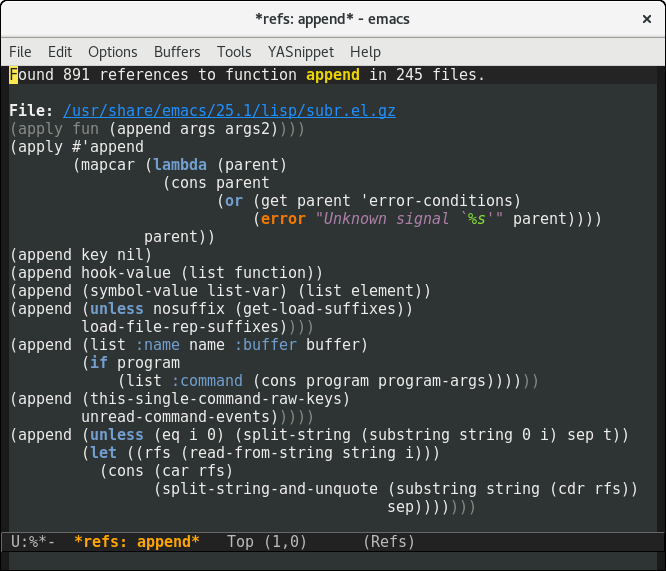 最后一个用户界面,使用普通的语法高亮显示
最后一个用户界面,使用普通的语法高亮显示
最终版本使用了标准的elisp高亮显示,但将周围的上下文作为注释进行高亮。这意味着它将匹配你最喜欢的配色方案,新用户应该会觉得用户界面很熟悉。
我还添加了一些其他的花饰。你可以看到,第二个原型中的结果往往是缩进得非常厉害。最终的版本将对每个结果进行反缩进,使匹配更容易快速阅读。
总结
elisp-refs is 可以在GitHub上获得, 也可以在MELPA上获得, 它现在随时准备为你服务! 来吧, 搜索你的 elisp!
