探索Emacs的chart库
条形图
条形图是一种通过彩色矩形对数据进行可视化分组的简单方法。在文本缓冲区和shell输出的世界中,我们很惊喜地发现Emacs居然有一个库可以用来绘制彩色矩形: chart.
(require 'chart) (chart-bar-quickie 'vertical "Favorite Type of Movie" ;; Type & Title '("Comedy" "Action" "Romance" "Drama" "Sci-Fi") "Genre" ;; Keys & Label '(4 5 6 1 4) "People" ;; Values & Label )
Rendering chart...done
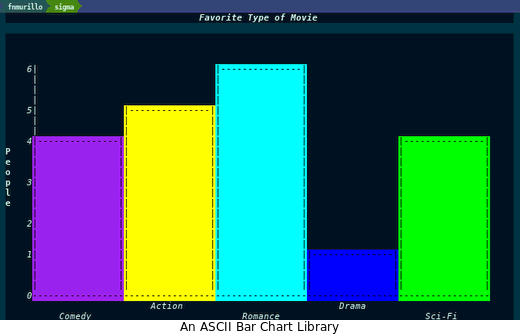
正如上面的截图所示,它还不够精致,不足以进行深入的检查,但在文本缓冲区范围内仍然令人印象深刻。
这个库是内置了一些关于Emacs解释器的有趣查询,比如如 memory-usage.
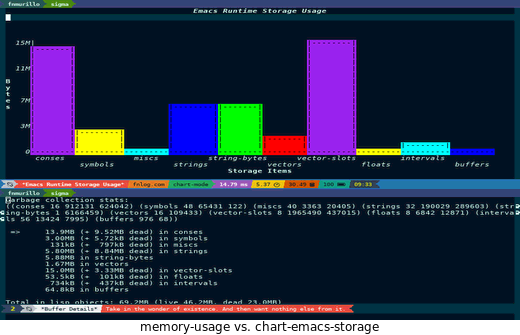
如果您想尝试一下,可以使用命令 load-library 来导入 chart.它定义了下面的演示命令可供你把玩:
chart-emacs-storage- 这个图表显示了内存使用情况
chart-emacs-lists- 与
chart-emacs-storage类似,他会对Emacs会话中的 buffer /, /frames/, /processes/, /faces/和/x-display 进行计数 chart-rmail-from- 与
rmail连用,它通过邮件对用户发送方的事件进行分组 chart-space-usage- 选择一个目录之后,它会根据该目录中的文件类型显示磁盘使用情况
chart-file-count- 选择目录之后,它会显示目录中个文件类型出现的次数
chart-test-it-all- 测试正负值的图表
除了这些演示命令之外,我们如何使用它来制作图表呢?
创建图表
经过一番阅读和探索,我发现理解这个库的起始命令或函数是 chart-bar-quickie,其余函数的似乎都是内部使用的。
虽然这个函数总共有只有8个参数,其中两个还是可选的,但是它封装了创建图表所需的一切,包括标签和数据,而不需要对 类 和 对象 实例化。下面用一个小代码段来演示一下:
(defun fn/chart-comparator-< (left right) "A sample comparator for the values. Each parameter is a key-value cos pair and should function as a comparator like `<', `=', or `>'." (pcase-let ((`(,left-key . ,left-value) left) ;; left is a cons of key and value (`(,right-key . ,right-value) right) ;; ditto with right ) (< left-value right-value))) (chart-bar-quickie 'vertical ;; Chart direction, either 'vertical or 'horizontal "Chart Title" ;; Chart title '("Alpha" "Beta" "Gamma" "Delta") ;; X-Axis values or keys "X Line" ;; X-Axis label '(4 3 2 1) ;; Y-Axis values "Y Line" ;; Y-Axis label ;; Optional 3 ;; Max value allowed, anything higher is not shown #'fn/chart-comparator-< ;; Sorting or ordering function )
Rendering chart...done
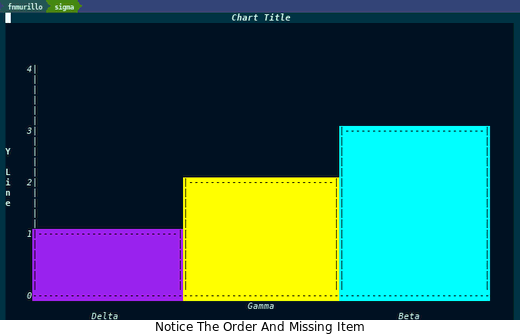
求值之后,就会根据标题创建一个新的缓冲区,并在那里呈现条形图。
不像 tabulated-list-mode 或其他特殊的缓冲区模式,显示本身是静止不动的,所以不要期望有特殊的快捷键或命令来排序、缩放、刷新图表。
除了不要报太大预期之外,所有主要(如果不是全部)功能都在该功能中。(遗憾的是,再怎么深入了解也产生不了更多的感悟)。
最后,这里唯一需要注意的是,键和值的数量应该是相同的,这很自然,因为它需要将每个键与相应的值匹配起来。
演示
作为一个例子,让我们处理一个数据集上的统计查询。我们将使用头发眼睛颜色数据集,它看起来像这样:
"","Hair","Eye","Sex","Freq" "1","Black","Brown","Male",32 "2","Brown","Brown","Male",53 "3","Red","Brown","Male",10 "4","Blond","Brown","Male",3 "5","Black","Blue","Male",11
在查询之前,让我们先导入数据,这是一个很好的在Emacs上解析CSV的练习:
(setq csv-dataset-file (expand-file-name "HairEyeColor.csv" "~/Downloads")) (defun read-lines (file) ;; Take your pick: custom, find-file, f-read-text (with-temp-buffer (insert-file-contents-literally file) (split-string (decode-coding-region (point-min) (point-max) 'utf-8 t) "\n" t))) (defun read-csv-field (field) ;; Remove the pesky enclosed double quoting (cond ((zerop (length field)) "") ((and (string-equal (substring-no-properties field 0 1) "\"") (string-equal (substring-no-properties field -1) "\"")) (substring-no-properties field 1 -1)) (t (string-to-number field)))) (defun read-csv-line (line) (let ((raw-fields ;; This assumes no rogue commas need escaping (split-string line ","))) (mapcar #'read-csv-field raw-fields))) (defun read-csv-file (file) (mapcar #'read-csv-line (read-lines file))) (setq dataset (read-csv-file csv-dataset-file)) ;; Generated output (("" "Hair" "Eye" "Sex" "Freq") ("1" "Black" "Brown" "Male" 32) ("2" "Brown" "Brown" "Male" 53) ("3" "Red" "Brown" "Male" 10) ("4" "Blond" "Brown" "Male" 3))
有一些专业的库,如 csv, el-csv 或 parse-csv,以及诸如 f 或 parsec 这样的实用程序,但是偶尔自己动手可以复习基础只是。
数据在手后,我们能对数据提出那些问题呢? 眼睛颜色的频率是多少? 在此之前,我们需要对数据进行分组:
(setq headers (car dataset) ;; Only mentioned, not needed records (cdr dataset)) (defun group-by (f xs) ;; A quick write on -group-by (let ((groups (list))) (mapc (lambda (x) (let* ((key (funcall f x)) (key-group (assoc key groups))) (unless key-group (push (cons key (list)) groups) (setq key-group (assoc key groups))) (setcdr key-group (cons x (cdr key-group))))) xs) groups)) (defun group-records-by-eye-color (records) (let* ((raw-eye-groups (group-by (apply-partially #'nth 2) records)) (eye-groups (mapcar (lambda (eye-group) (pcase-let ((`(,eye-color . ,eye-records) eye-group)) (let ((eye-frequencies ;; Extract frequencies and collect it (mapcar (apply-partially #'nth 4) eye-records))) (cons eye-color (apply #'+ eye-frequencies) ;; Shiv for sum )))) raw-eye-groups))) eye-groups)) (setq eye-color-groups (group-records-by-eye-color records)) ;; Generated output (("Green" . 64) ("Hazel" . 93) ("Blue" . 215) ("Brown" . 220))
在提取之后,获取柱状图就很简单了。
(chart-bar-quickie 'horizontal "Eye Colors" (mapcar #'car eye-color-groups) "Colors" (mapcar #'cdr eye-color-groups) "Frequency")
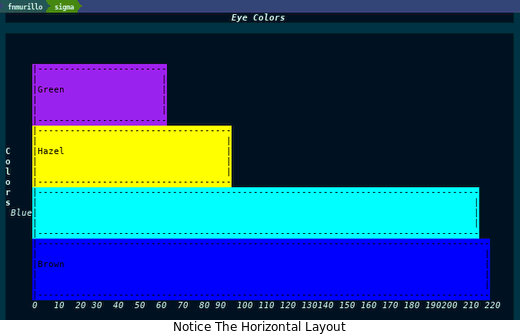
很漂亮,但再让我们按降序排列一下:
(defun on (f op) ;; Haskell's on operator (lexical-let ((f f) ;; Sad that parameters aren't lexically scoped here (op op)) (lambda (left right) (funcall op (funcall f left) (funcall f right))))) (chart-bar-quickie 'horizontal "Eye Colors - Descending" (mapcar #'car eye-color-groups) "Colors" (mapcar #'cdr eye-color-groups) "Frequency" nil (on #'cdr #'>) ;; A comparator lambda also works but done for variety )
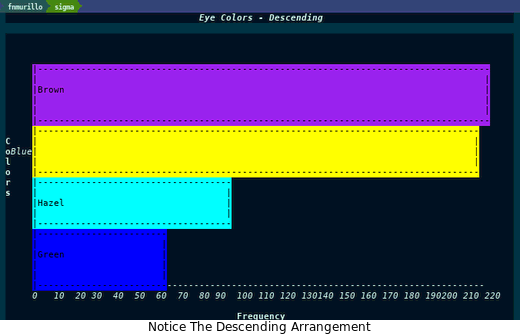
看看这幅图,/棕色/ 和 蓝色 的眼睛很常见。没有什么突破性的或史诗般的东西。用同样的方法处理 发色 怎么样?我们得到如下图表:
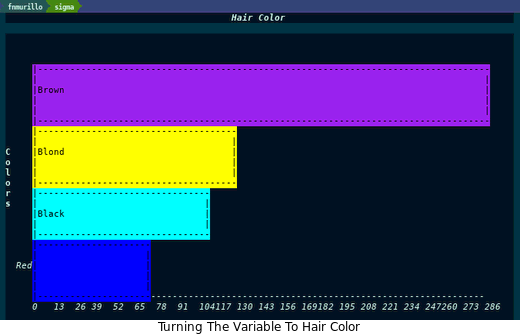
以 头发颜色 为变量,我们发现 棕色 和 金发 特别多。这没什么奇怪的。 我们可以把变量改成 gender,但没什么意义。 任何可视化的真正问题是 它意味着什么? 或者说,我们能从数据中解读出什么见解? 因为它只是一个样本,它可能没有任何意义,也不需要有任何意义。这是一个图书馆式的探索,而不是一个超出范围的统计学课程。
